Colin's Journal: A place for thoughts about politics, software, and daily life.
April 8th, 2003
Thoughts on a publish-subscribe service for RSS
A posting by Dan on the way we use RSS to notify users about updates to weblogs inspired me to consider an alternative. It’s not immediately clear that the polling of a web-server once an hour using conditional GET of an RSS feed is really a problem. As I say in the starting paragraph of my new article on the subject:
I’ve seen it estimated that a conditional HTTP GET on an RSS file takes about 200 bytes of bandwidth. That’s not very much at all, even with a thousand clients polling once per hour the total bandwidth cost in a month will be about 137MB. It’s still worth looking at alternatives though to see whether there is a more efficient way of being notified when a weblog is updated.
Is it worth the development effort required to reduce this kind of load? If we did, would it really work? I’m not convinced yet, but I have taken a stab at describing a web service that could by implemented as an alternative. I did consider existing alternatives like headline distribution in Jabber, but they still rely on polling at the end of the day.
Here’s my proposal, if you are interested in this sort of thing I would appreciate the feedback.
April 7th, 2003
A case study: Sods law
So there I was proudly stating that I had not had any kernel panics with the BeFS module, and how I had recovered my data when guess what happened? Yes, my music stopped, the screen stopped redrawing, and my keyboard did the “flashing all the lights” thing.
I’m not sure exactly what caused this kernel panic, but thankfully I don’t seem to have lost any data. The floppy drive has been on the way out for a while, and when I rebooted it was making a very sickening screeching noise. I’ve unplugged it for now, and I think I’ll get a replacement. So was it the module, the floppy, or something else entirely? Not sure…
April 7th, 2003
Digital Archaeology, or how I rescued my email
Many moons ago (approximately sixty by my reckoning) I bought myself a new computer, and having very carefully selected hardware that was supported, I installed BeOS. It was a fun, fast, life enriching operating system that was blazing the trail to a bright future. It also had very few applications that ran on it, and tended to crash rather a lot, particularly when web browsing.
BeOS came with it’s own disk file system (BFS), it’s own way of handling email (single file per message), it’s own “almost a database” way of organising data, and many other fancy features. As the fortunes of the startup behind the o/s waned, and Be Inc started laying off staff and changing direction, I started looking for an alternative.
I ended up choosing Linux, and found myself on a frustrating, slow, life shortening operating system that had many unfinished applications, and a web browser that tended to crash a lot. Thankfully as time progressed Linux has improved in leaps and bounds, to the point where there are lots of finished applications and browsing the web almost never leads to crashes.
During my migration to Linux I kept my existing BeOS installation to one side, thinking that one day I must really go back and retrieve my data off it. Several hardware upgrades later however, and I found that I couldn’t boot into BeOS anymore. I retrieved the boot CD and floppy from the other side of the Atlantic, and found that I still couldn’t boot into BeOS. So much for my data…
A couple of weekends ago I found a Linux module that handles BFS (or BeFS so as not to be confused with the other BFS that’s out there…) I compiled, installed, and tried to mount my BeOS partition. It worked! No kernel panic, no errors loading the module, just a mounted file system with all my data sat there.
Since then I’ve been going through my old BeOS system and pulling out various parts of it that I would like to keep around. I also discovered somethings that I had forgotten doing, like writing a POP3 client to handle downloading email (written as a work around for a bug in the client that shipped with the system).
Among the old data were all my old emails (a little over five thousand of them), but they were stored in a format that Evolution (my email client) refuses to read. Thankfully the format is very simple (full email text as a single file), and the mbox format that Evolution does understand is equally simple. I’ve written a tiny Python script to convert BeOS Mail to mbox format, and after a few iterations to shake out the bugs it has worked well enough to restore all my old email.
I’ve now got just over 19,000 emails in my system, dating back to June 1998, and hopefully I’ll be able to keep these around for many years to come. Just remember when transitioning systems that you need to move your data over as soon as is possible, because it only gets harder as time goes on…
April 5th, 2003
Free RSS Aggregator Released!
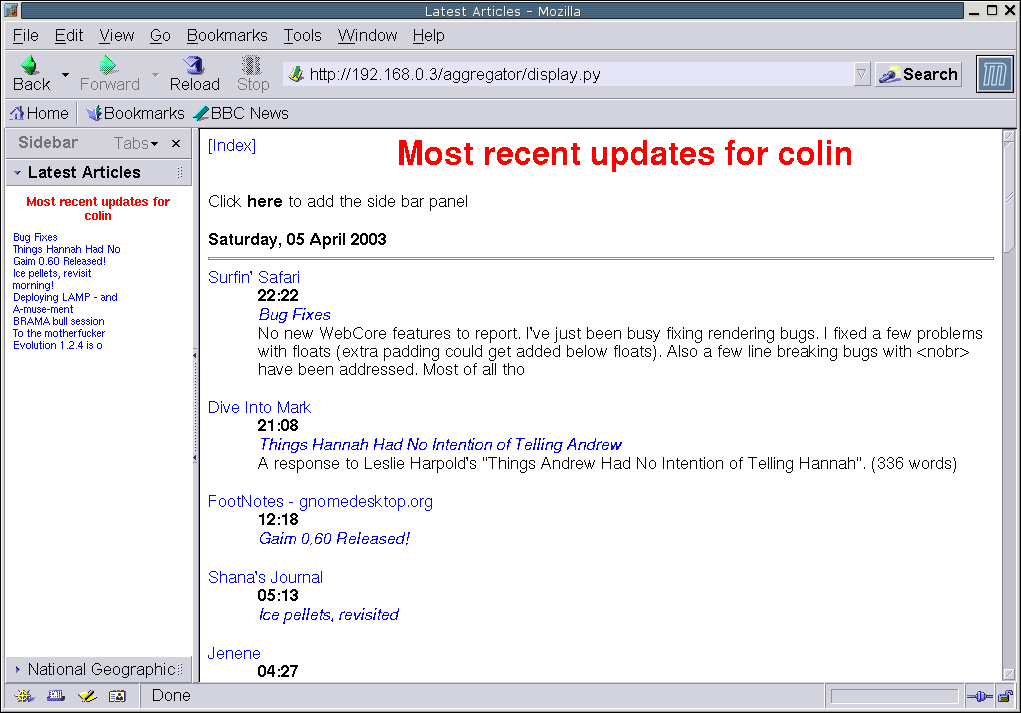
I’ve finished packaging together my RSS Aggregator. It’s at a point where you can use it on an every day basis without hacking code or fiddling with the database.
I’m releasing it on the off chance that someone else might need software that does a similar sort of thing, it would be a shame for two people to have to write it!
If you are curious as to what it looks like, here’s a screen shot of my “recently updated articles” page.
April 4th, 2003
Deploying LAMP – and holding back the flooding
Deploying a LAMP (Linux, Apache, MySQL, Python/Perl) application is difficult. I’ve just put together the briefest description of how to install my web-based, multi-user, RSS aggregation application – and frankly it requires a Unix administrator to do it. I new it would be difficult (I wrote this for myself, I’m just planning on releasing it on the off chance that someone else might want/need a similar thing), but when you finally write a document which describes the steps it’s driven home.
For a start there are eight different software packages that it depends on, although it’s a fair guess that four of them are installed by the distribution of Linux you are using (in theory this is cross platform, but that’s just one complication too far). Then there is database creation, schema creation, basic configuration data setup, the apache configuration, and finally the application configuration. Then you can log-in to the system and start using it…
I see that there is going to be an attempt to stop the worst of the flooding that happens to Venice. I don’t know enough about the politics and plans surrounding this to comment on the significance of this particular announcement, but it does raise a thought. I wonder how many other dynamic flood defences like this exist in Europe? I know about the Thames Barrier, but there are probably others…
April 2nd, 2003
More thoughts on BitTorrent
Firstly it should be made clear that BitTorrent itself is not a piracy tool. It has many perfectly legitimate uses for transferring large files whose author has given permission for such free distribution. Having said that there do appear to be many easily accessible sites, such as this and this, that are hosting the information required to get access to TV series, films, and music which can not be legally distributed freely.
These sites only hold the .torrent files, which as I explained in an earlier post do not actually contain the copyrighted material. They instead point to a central server, which in turn keeps track of those IP addresses that are involved in distributing the material. It’s surprising that these sites have not been taken down yet, they are not hard to find, and while not many people have the time or bandwidth to download ~1GB files, the number which can is growing steadily.
It’s possible that, if the owners of one of these sites actually had the money available to take such a matter to court, there would be some countries where the hosting of these .torrent files would be found to be legal. They do not after all tell you directly where copyrighted material can be found, they simply point to an IP address that in turn lists people who do have such material. In most places this argument would probably fail, but you only really need one or two jurisdictions in which it’s legal to host these files, and they will continue to be available.
Those running trackers are far more vulnerable, they are the closest thing to the central server used by Napster. The major difference is that while Napster had one central location that everyone knew about, with BitTorrent you can have many different trackers managing different or overlapping sets of files.
This means that while individual legal victories might be had at any level of the BitTorrent architecture (torrent hosts, trackers, or peer-to-peer clients), it would be very hard to stop the distribution of copyrighted material this way. However by taking action against the torrent hosts it would slow down the spread of such material, pushing the location of .torrents underground onto IRC and other such networks. Ensuring that getting the material is more difficult than a search on google would be at least a tactical victory for those trying to suppress the free distribution of copyrighted material.
April 2nd, 2003
Games of chance
Both Sunday evening and last night were spent playing various Cheap Ass games, and on the off chance that you have never heard of them before, be assured that they are great fun indeed. One of the new ones that we picked up at Ad Astra is Witch Trial, a fun card game with significant gambling elements, and a touch of role play to keep things interesting.
The premise of the game is that you are a lawyer during the witch trials in the US, and you are out to make money by prosecuting and defending cases. The play is varied enough that I think we’ll come back to playing it many times again in the future, joining Kill Doctor Lucky as a classic.
April 1st, 2003
BitTorrent and distributing large files
I’ve heard about BitTorrent before, but it was only today that I saw a great example of how it can change the nature of distribution of large files on the Internet. Red Hat released ISOs of version 9 of their Linux distribution to paying subscribers, and someone (legally) made them available through BitTorrent and announced their availability on slashdot. The result was that people could get hold of the ISOs through the peer-to-peer swarm more quickly than they could through the overloaded FTP site.
The reason the peer-to-peer network was faster is down to the way BitTorrent works, which is that each downloading client also becomes a provider of the file. A major strength of BitTorrent is that the downloading client doesn’t have to complete the download before it can offer uploads, whatever portions have already been downloaded are made available for upload to others in the swarm that might need them.
The architecture consists of three main components. The .torrent file contains a description of the file (or directory) that is to be downloaded, including name, file size, and a secure hash of each chunk of the file. It additionally contains the URL of a BitTorrent tracker.
The tracker maintains a list of peers currently involved in transferring a particular file (or directory), as well as some stats around what each peer is up to. The client, after parsing the .torrent file, connects to the tracker and gets the list of peers in the swarm. The client then contacts peers from this list directly, offering up portions of the file that the client already has, and asking for portions that it requires.
There is some load balancing to ensure that clients are uploading their fair share, you get faster downloads the more bandwidth you can provide on upload, and multiple downloads are performed at once (so enabling modem users to make a real contribution of bandwidth even to those on broadband connections).
It’s an excellent way of distributing large files without having to foot a huge bandwidth bill.

{kind=link}
Software
The full list of my published Software
Email: colin at owlfish.com